Intro
Way back in the beginning of this blog, I wrote about the definition of the term “Pragmatic”. From the all-knowing Google, we have this definition:
– dealing with things sensibly and realistically in a way that is based on practical rather than theoretical considerations.
One of the best ways to achieve this definition is in software is to be able to demonstrate what our code does. If we can demonstrate that our code works, it becomes a real thing and is no longer theoretical. If we can make sure that our code works in a way that is easily repeatable, all the better. I have, in past post, written about the value of testing and I won’t go into it again here. The important point is that a sure path to writing pragmatic software is to write tests that can be repeated.
In recent years, Docker container have become increasingly popular and, fortunately, increasingly stable and easier to use. Docker containers can be thought of as a sort of light-weight virtual machine that helps developers standardize dependencies and environments that their code runs in. While Docker containers can be used in a number of different ways, one way that I am particularly fond of is using them to spin up application dependencies while running local integration tests.dependencies
To be clear, there is still some effort that goes with using docker containers. They are not a silver bullet, and they are not magic. For example, they don’t somehow magically provide your development machine with more CPUs or more memory that it already has. Also, spinning up the containers also raise additional considerations, not the least of which is managing networking and ports. That said, I believe that getting docker containers work as part of our integration testing strategy is not a bad idea. So, let’s take a little bit of a look at how to go about doing that.
The next few steps will discuss installing and running Docker. For a more complete overview, check out https://docs.docker.com/engine/getstarted/.
Install Docker for Mac
The first step in working with Docker on the Mac (my platform of choice) is to install Docker. Fortunately, this has become much much easier with the advent of the native release of Docker for Macs. Prior to this last release, Docker and a Mac meant using docker-machine and virtual box. Essentially this was running docker in a VM on Mac OS X. It was a bit complicated. Now, however, installing docker is very simple. For more info, check out: https://www.docker.com/get-docker
Create Dockerfile
Once you have docker on your machine, there are basically two steps involved in using it. The first step is to build a docker image. Images are built based on definitions that are stored in a “Dockerfile”. For the minitron app, I am using Postgres as my database engine. As it turns out, there is a pre-build Postgres docker file that I can use…
https://hub.docker.com/_/postgres/
Once I have the file, the next step is to build the docker image.
Note: I could have also downloaded an image from Docker Hub. See the tutorial mentioned above for examples and info on how to do that.
Build Docker Image
A “Dockerfile” defines how a docker image should be constructed. Once an image is built, we can re-use that image as much as we like. This makes using docker fairly speedy. In order to build the Postgres image from its docker file, we can issue a command like this:
(From the same directory as the Dockerfile I am using.)issue
> docker build .
This will kick off the process of building the new image. It will take a while, but only the first time we wish to build these images.
In a bit, I’ll discuss a bit more about how we are going to use this docker image as part of our integration testing. However, just running postgres is not going to be enough to support our integration tests. The tests will depend on having database tables created as well. Here we have a couple choices. We could, if we choose, build the creating of the tables into the docker image that we are using. We could also use the initialization process of the docker images when they are run via a technique called entry-points. Lastly, we could handle the creation of the database tables our selves in code. Since this is a fairly small application, I am going to manage the database structure in the code. That said, I am not suggesting that is always the best way to go. Database schema management is an issue all unto itself and is beyond the scope of this blog post. One thing that I will mention is that there has been increasing discussion and use of Liquibase as a tool for managing database schemas. I’ll let you read more about it here… http://www.liquibase.org/
Write the Database Creation Script
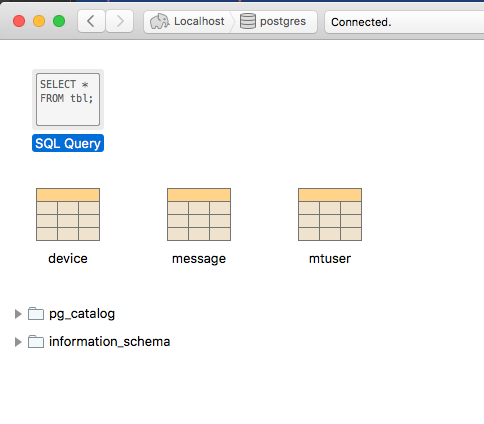
For the minitron database, we will have essentially 3 tables. Each table will have a primary key (that we will generate in code via UUID) and possibly some uniqueness constraints on columns. I wrote a very simple helper class that connects to postgres and then reads thru and executes sql statements in a file. (I could have used the psql CLI for that, but since I am going to be creating and tearing down the database from tests, this seemed to be a reasonable approach.) So, here is what our databaase schema looks like:
DROP TABLE IF EXISTS mtUser; CREATE TABLE mtuser( userId text, email text, password text, PRIMARY KEY( userId ) ); CREATE UNIQUE INDEX user_key ON mtuser USING btree (userId); CREATE UNIQUE INDEX email_key ON mtuser USING btree (email); DROP TABLE IF EXISTS device; CREATE TABLE device( deviceId text, deviceCode text, userId text, PRIMARY KEY( deviceId ) ); CREATE UNIQUE INDEX device_key ON device USING btree (deviceId); CREATE UNIQUE INDEX deviceCode_key ON device USING btree (deviceCode); DROP TABLE IF EXISTS message; CREATE TABLE message( deviceId text, channel integer, message text, messageId text, PRIMARY KEY( messageId ) ); CREATE UNIQUE INDEX message_key ON message USING btree (messageId);
Switching back to docker…
If you recall from above, I created a docker image that holds my postgres server. In order to test my script above, I can fire up docker from a command line and use a GUI client ( or CLI) to see if my database creation script works. I can do that with this command (which is all on the same line…)
docker run –name some-postgres -e POSTGRES_PASSWORD=secret -d -p 5432:5432 postgres
Now from my GUI (in my case, Postico) I can debug the script above.
Start Docker from a Springboot Integration Test
At this point, I have my Dockerfile, my image, and a script to create the database. All I need to do now is to incorporate all of this into a test. Easy right? Well….
Actually it is not too bad. Let’s start with the test:
…
@DockerDependent
@SpringBootTest(classes = MinitronApplication.class,
webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
class UserControllerSpec extends Specification {
@Shared
def RESTClient restClient
@Value(‘${local.server.port}’)
int port //random port chosen by spring test
def setupSpec() {
DatabaseUtil dbUtil = new DatabaseUtil()
dbUtil.createDatabase()
}
def setup() {
UserDao userDao = new UserDao()
userDao.clean()
restClient = new RESTClient(“http://localhost:${port}/”)
restClient.handler.failure = { resp -> resp.status }
}
def ‘I can save a user.'() {
given:
restClient != null
when:
def resp = restClient.post(path: ‘user/mporter@paintedharmony.com’,
body: ‘thisIsAPassword’,
requestContentType: ContentType.JSON)
then:
resp.status == 201
}
A couple of notes:
The @DockerDependent annotation does all of the heavy lifting in order to fire up my database. I am using a docker-compose.yml file to specify the parameters of my database much in the same way that I used command line switches when I did docker run. My docker-compose.yml looks like this:
version: '3'
services:
# ------------------------------------------
postgres:
image: asimio/postgres:latest
ports:
- "5432:5432"
environment:
POSTGRES_PASSWORD: secret
POSTGRES_USER: postgres
Because this is a yaml file, the spacing is very important!
One the database is up and my annotation is finished, I initialize the database with the help fo the databaseUtil file.
Finally, when we are all finished, the @DockerDependent annotation tears down everything and makes sure that docker is done.
I have found that, when playing with docker, it is very important to keep track of what docker containers are running, and also what networks have been configured. To that end, it is somethings helpful to have a script that can clean up docker stuff that gets left hanging around. Here is one that I am currently using from time to time…
#!/bin/bash
echo “stopping and removing ALL docker containers”
for dockerid in $(docker ps -qa); do
echo -n “stopping ”
docker stop $dockerid
sleep 2
echo -n “removing ”
docker rm $dockerid
done
echo “cleaning out volumes”
docker volume rm $(docker volume ls -q)
echo “cleaning out dockertest networks”
docker network rm $(docker network ls -qf ‘name=dockertest*’)
Conclusion
Docker is a very powerful tool that can really help with developing services and microservices. While it plays a huge role in the container world, it can also be an appropriate technology to use to spin up dependencies required by integration tests.
As always, source code for this app (which is a work in progress) can be found here:
https://github.com/fractalbass/minitron

One thought on “Springboot Integration Testing with Dependencies Running in Docker”